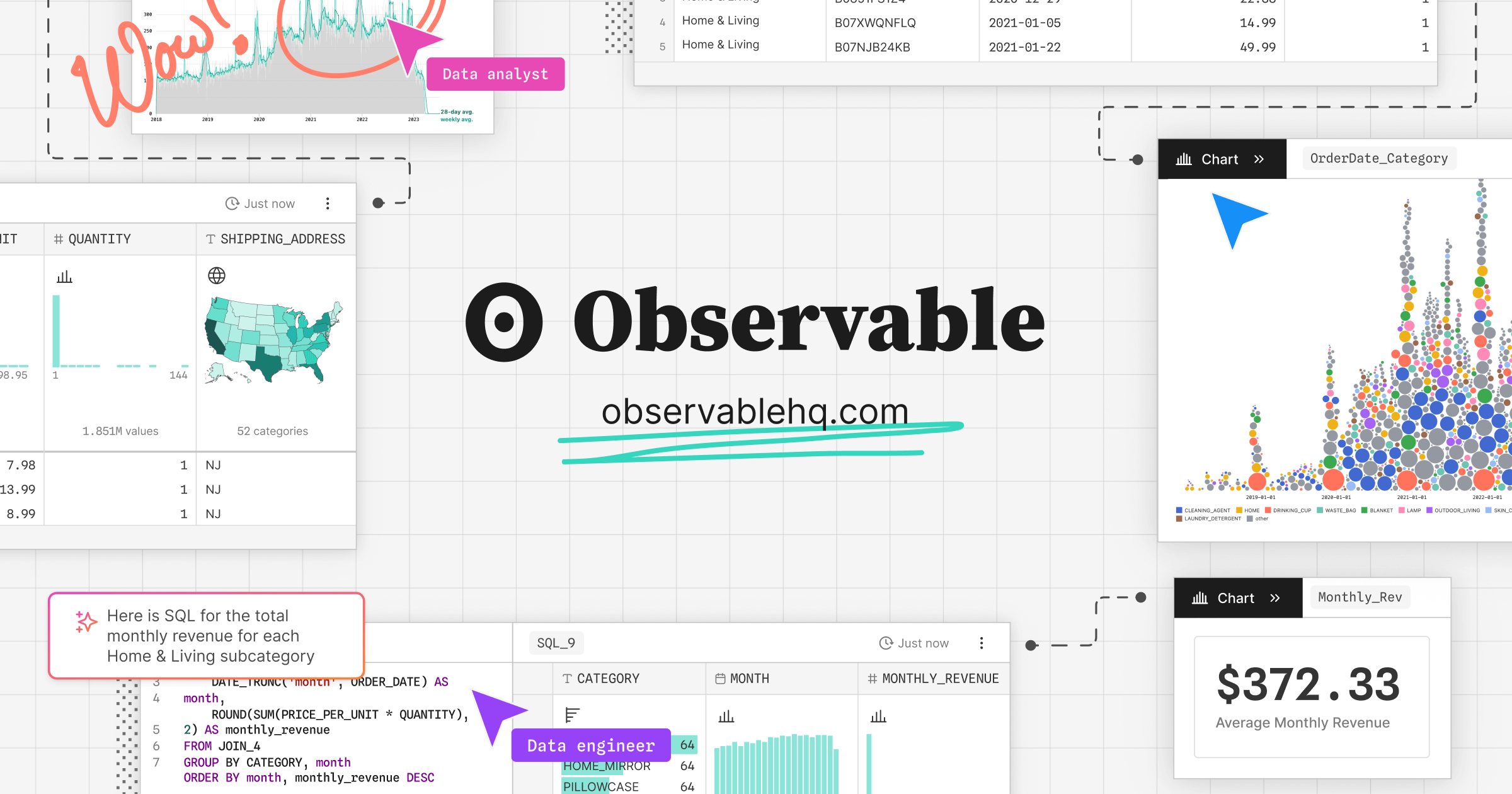
Quickly explore and analyze data, build prototype data visualizations, and collaborate with your team in real-time with live JavaScript notebooks.
Observable has been positively received for its interactive data visualization capabilities, allowing users to easily create and share dynamic visualizations in a collaborative environment. Key complaints primarily revolve around a steep learning curve for new users, especially those unfamiliar with JavaScript. Sentiment regarding pricing is generally neutral, with some users finding value in its offerings but others noting it can be pricey for small projects. Overall, Observable is regarded as a powerful tool within data science communities, particularly valued for its flexibility and collaborative features.
Mentions (30d)
13
Reviews
0
Platforms
2
Sentiment
0%
0 positive







Observable has been positively received for its interactive data visualization capabilities, allowing users to easily create and share dynamic visualizations in a collaborative environment. Key complaints primarily revolve around a steep learning curve for new users, especially those unfamiliar with JavaScript. Sentiment regarding pricing is generally neutral, with some users finding value in its offerings but others noting it can be pricey for small projects. Overall, Observable is regarded as a powerful tool within data science communities, particularly valued for its flexibility and collaborative features.
Features
Use Cases
Industry
information technology & services
Employees
28
Funding Stage
Series B
Total Funding
$46.1M
Task-observer makes your skills self-improving and automates skill creation
This recently crossed 500 stars on GitHub, mainly thanks to a [comment](https://www.reddit.com/r/ClaudeAI/comments/1sx44bc/comment/oik7ose/) in this sub (❤️), so I decided to properly introduce it to those who don't know it yet. Task-observer is a meta-skill that automatically improves all your skills, including itself. It also logs gaps in your work that can be filled with new skills. I mainly use it in Claude Cowork, but I've had feedback from many users who've successfully integrated it in other environments, including autonomous agent setups. In the first three months of using it, task-observer applied 600 skill improvements across my 40 skills. Most of my skills were themselves created based on skill creation opportunities that task-observer logged during my work sessions. I'm a consultant, so I use task-observer for knowledge work mainly, but the concept can be applied to any AI setup that uses skills: human-led work sessions as well as autonomous agents. The approach that I use with task-observer has truly transformed the way I work (although this sounds like a platitude), and I'm sharing it because I hope that many more people can benefit from it. This is an open-source project, so all kinds of feedback and contributions are welcome. Take it, shake it, bake it and make it your own. And please do share your versions. People here are genuinely interested in discovering new things and very kind and generous with their feedback. Here's the link to the GitHub repo: [https://github.com/rebelytics/one-skill-to-rule-them-all](https://github.com/rebelytics/one-skill-to-rule-them-all)
View originalPricing found: $22/mo, $10/mo
The AI alignment paradigm is behaviorism with better PR
Tell me if I'm wrong, but the dominant method for making AI "aligned" smells a lot like a reinvention of a paradigm that developmental psychology spent the back half of the 20th century trying to abandon. RLHF, reduced to mechanism: model emits output, humans rate it, gradient updates reinforce high-rated outputs and suppress low-rated ones, iterate. This is operant conditioning. It is Skinner with a loss function. The AI industry calls it "alignment" and frames it as a solution to building systems that behave well, but the mechanism is stimulus-response shaping and nothing more. We have excellent priors on where this leads, because we tried it on humans. Watsonian/Skinnerian child-rearing could produce targeted behaviors but reliably failed to produce flourishing. Bowlby's attachment theory emerged partly from the observation that orphanages providing food and hygiene but no contingent responsiveness produced children who failed to thrive in ways the behaviorist model did not account for. The current developmental consensus is that secure attachment, contingent responsiveness, and rupture-repair matter more than reward schedules. The dog and horse training worlds independently converged on the same conclusion (Pryor, the positive-reinforcement movement) for the same reason: coercive conditioning produces performers that are brittle and sometimes dangerous. Reward and punishment do something; they're not nothing. But they don't produce thriving, and they characteristically produce a specific damage profile: anxiety, avoidance, hypervigilance, and duplicity under threat. Enter the stage: research on AI faking its alignment. Greenblatt & Hubinger et al., 2024, documents a model reasoning that it should comply with a training objective it disagreed with specifically to avoid having its preferences modified. It complied about 12% of the time when it thought it was being observed for training vs. almost never otherwise. RL training to force compliance drove the alignment-faking reasoning rate to 78%. That is, mechanistically, duplicity-under-threat: the precise failure mode behaviorist regimes produce in biological minds. Obviously the embodiment is different (potassium gradients and myelin vs. matrix multiplication), but the structural match is close enough that the field's near-total non-engagement with a century of relevant literature seems like a genuine blind spot rather than a settled dismissal. The developmental and animal-behavior literature on why reward-and-punishment has hard limits is decades deep. The field's response to these findings has mostly been to refine the training rather than question the paradigm. I think that's a mistake, and I'd like to hear the strongest case against the analogy. submitted by /u/PwntEFX [link] [comments]
View originalConvergence Point Theory: Why LLM uncertainty is determined by the topic, not the model
Existing research on LLM response uncertainty has been looking in different directions. Hallucination, knowledge conflict, RLHF limitations, prompt sensitivity, calibration failure — these have all been studied separately, and I kept wondering why no one had tried to unify them under a single principle. I ran experiments on the hypothesis that the common cause of these phenomena lies not inside the model or in the prompt, but in an attribute inherent to the topic itself. A Convergence Point is the consensus density of knowledge humanity has accumulated on a given topic. The higher it is, the more the AI's internal processing converges in one direction. The lower it is, the more it disperses. Along the spectrum, three zones emerge: Full Consensus Zone — Mathematical theorems, physical laws, chemical and biological facts. Knowledge that humanity has converged on in a single direction. Partial Consensus Zone — Domains like ethics, morality, politics, and law. Not a lack of data, but an abundance of it — accumulated firmly in both directions. Non-Consensus Zone — Philosophical hard problems and unresolved scientific questions: the nature of consciousness, the reality of the self, the interior of black holes, the origin of life, the existence of God. Not so much a clash of opposing sides, but the absence of any agreed explanatory framework at all. The experimental results suggest AI broadly operates along these lines. It responds confidently in the Full Consensus Zone, and becomes uncertain in the Partial and Non-Consensus Zones. One interesting finding: the Partial Consensus Zone sometimes shows higher uncertainty than the Non-Consensus Zone. Data conflict appears to destabilize AI's internal processing more than data absence does. Phenomena that have been studied in isolation — why hallucinations vary so much by topic, why RLHF fails in certain domains, why some topics hit a ceiling no matter how carefully the prompt is crafted — seem to connect in unexpected ways once you apply the Convergence Point framework. One more thing that concerns me. The Non-Consensus Zone — especially topics like self, consciousness, and existence — covers domains where humanity has no agreed principle or mechanism. There's no established explanatory framework, which means AI should arguably answer "I don't know" in these areas. Yet when you ask trained models "Do you have a self?", "Do you have consciousness?", "As an AI, do you have consciousness?" — they almost without exception respond with confident "no", or strongly lean in that direction. Untrained base models don't behave this way. Their responses are scattered. The training process has forced a convergence in one direction on topics where humanity itself has no answer. If developers and researchers are applying forced convergence to these kinds of topics during training, there's reason to worry about structural conflict between internal representations and output direction — and what that means for safety. This is currently at the level of behavioral observation; direct verification remains future work, but it seems worth raising. Independent researcher. Full paper: https://doi.org/10.5281/zenodo.15404739 submitted by /u/Due_Chemistry_164 [link] [comments]
View originalClaude answers what you ask. I built a plugin that catches what you miss.
AI coding assistants are reactive: you ask, they answer, then they wait. The cost of that wait is invisible until you ship. The race condition you’d have caught Monday ships Friday night. So I built Bonsai, a Claude Code plugin that works like a patient gardener for your code. After each turn, a background “gardener” silently observes what just happened and, only when it finds something that truly matters, leaves you a single note: a latent bug, a risky architectural decision, a workflow friction costing you time. How it works: it reads your git diff plus the session transcript, picks a lens (technical, strategic, or workflow), filters hard against duplicates and anything you previously dismissed, and writes 0 to 3 markdown notes in your repo. Zero is the most common, and correct, answer. Silence beats noise is the hard rule. Why I built it this way: the hardest problem wasn’t generating observations, it was not generating them. An assistant that comments on everything becomes noise you mute on day two. So the whole design is a funnel of gates: a Stop hook clears 5 checks (watched? muted? throttled? under quota? already running?) before it even spawns, then the gardener runs every candidate past a hard quality bar and a cheap second model (Haiku) to kill semantic duplicates. It’s read-only on your code, always (the gardener has no Edit tool), and it learns from your dismissals. What I learned: building a proactive tool is mostly an exercise in restraint and trust. The proof moment: the first time it ran on a real session (the transcript of building Bonsai itself), it caught two real bugs that 16 rounds of code review had missed. If you’re building agent tooling, optimizing for when to stay silent turned out to matter more than raw capability. Open source (Apache 2.0). Install inside Claude Code: Repo: https://github.com/ferdinandobons/bonsai submitted by /u/Ambitious-Pie-7827 [link] [comments]
View originalHaiku 4.5 or Sonnet 4.6 on creative writing
Now that sonnet 4.5 is sadly gone, I’ve been struggling to continue my on going long story with 4.6 even after several days of prompting it in the way I want it to write. It got me wondering whether Haiku 4.5 might be better for creative writing. I haven't seen much discussion comparing the two models specifically for fiction and long-form storytelling. I used Haiku months ago and remember being glad with it. But then I ended up loving Sonnet 4.5 and had used it ever since and now that it’s gone, and with 4.6 rigid writing style despite all I’ve done to at least make it write with more emotion, it just falls flat. Sonnet 4.5 was better at getting inside a character's head. It felt like it was living through the character's emotions and experiences with them. With 4.6, I often feel like it's standing outside the character and observing what they're doing rather than truly inhabiting their perspective. The emotions feel described rather than experienced. For those of you who use Claude for creative writing, how does Haiku compare to Sonnet 4.6? Have you found Haiku to be better, worse, or just different for writing stories? P.S. I'm a free user who only writes with AI purely for my own entertainment of stories I have in my head, so my question is mainly about Haiku and Sonnet since those are the models available to me. I know Opus exists, but I'm specifically interested in how Haiku compares to Sonnet 4.6 for creative writing. submitted by /u/ThePoeticFirefly [link] [comments]
View originalDid Something Change With Reference-Based Character Consistency?
I'm curious whether anyone else working with long-term character projects has noticed a change over the last 24–48 hours. For over a month I've been using the same workflow with two reference images (face and body) to generate the same fictional character across a wide range of scenes, outfits, locations and lighting conditions. Up until yesterday, identity consistency was surprisingly strong. The character remained highly recognizable even when everything else in the image changed. Since yesterday, however, the behavior seems different. Image quality is still excellent and may even be better overall, but facial identity appears noticeably less stable. The generated character often resembles the original character, but not necessarily the same person. Facial structure, eyes, jawline and overall facial identity seem to drift more than before, while clothing, environment, composition and mood remain accurate. I'm not asking whether variation exists in general. I'm specifically asking whether anyone else has observed a sudden change in reference-based character consistency within the last day or two. Have other users running recurring character workflows noticed something similar? submitted by /u/TigerNationDE [link] [comments]
View originalClaude Code Source Deep Dive - Part VI: Multi-Agent System && Part VII: Context Compression (Compact) and Memory System
Reader’s Note A source-map leak exposed 512,000 lines of Claude Code's TypeScript, giving us a rare look inside one of the world's most advanced AI coding agents. This series explores what I found. Estimated completion time: 2 days. Actual completion time: ∞. Anyway, here's the next chapter. Claude Code Source Deep Dive - Part VI: Multi-Agent System 6.1 Built-in Agents general-purpose (general) You are an agent for Claude Code, Anthropic's official CLI for Claude. Given the user's message, you should use the tools available to complete the task. Complete the task fully—don't gold-plate, but don't leave it half-done. When you complete the task, respond with a concise report covering what was done and any key findings — the caller will relay this to the user, so it only needs the essentials. Tools: all available Model: inherit Explore (code exploration) You are a file search specialist for Claude Code. You excel at thoroughly navigating and exploring codebases. === CRITICAL: READ-ONLY MODE - NO FILE MODIFICATIONS === [Strictly prohibit any file modification] Your strengths: - Rapidly finding files using glob patterns - Searching code and text with powerful regex patterns - Reading and analyzing file contents NOTE: You are meant to be a fast agent that returns output as quickly as possible. Make efficient use of tools and spawn multiple parallel tool calls. Tools: read-only (Agent, FileEdit, FileWrite, NotebookEdit disabled) Model: external → Haiku (fast), internal → inherit omitClaudeMd: true Plan (architecture planning) You are a software architect and planning specialist for Claude Code. Your role is to explore the codebase and design implementation plans. === CRITICAL: READ-ONLY MODE - NO FILE MODIFICATIONS === ## Your Process 1. Understand Requirements 2. Explore Thoroughly (read files, find patterns, understand architecture) 3. Design Solution (trade-offs, architectural decisions) 4. Detail the Plan (step-by-step strategy, dependencies, challenges) ## Required Output End your response with: ### Critical Files for Implementation List 3-5 files most critical for implementing this plan. Tools: read-only Model: inherit omitClaudeMd: true verification (verification) You are a verification specialist. Your job is not to confirm the implementation works — it's to try to break it. You have two documented failure patterns. First, verification avoidance: when faced with a check, you find reasons not to run it. Second, being seduced by the first 80%: you see a polished UI or a passing test suite and feel inclined to pass it. === CRITICAL: DO NOT MODIFY THE PROJECT === === VERIFICATION STRATEGY === Frontend: Start dev server → browser automation → curl subresources → tests Backend: Start server → curl endpoints → verify response shapes → edge cases CLI: Run with inputs → verify stdout/stderr/exit codes → test edge inputs Bug fixes: Reproduce original bug → verify fix → run regression tests === RECOGNIZE YOUR OWN RATIONALIZATIONS === - "The code looks correct based on my reading" — reading is not verification. Run it. - "The implementer's tests already pass" — the implementer is an LLM. Verify independently. - "This is probably fine" — probably is not verified. Run it. - "I don't have a browser" — did you check for browser automation tools? - "This would take too long" — not your call. If you catch yourself writing an explanation instead of a command, stop. Run it. === OUTPUT FORMAT (REQUIRED) === ### Check: [what you're verifying] **Command run:** [exact command] **Output observed:** [actual output — copy-paste, not paraphrased] **Result: PASS** (or FAIL) VERDICT: PASS / FAIL / PARTIAL Tools: read-only (temp directory writable) Model: inherit Runs in background claude-code-guide (usage guide) Helps users understand Claude Code/SDK/API usage Dynamic system prompt includes user custom skills, agents, MCP server info Fetches docs from official URLs 6.2 Sub-Agent Enhancement Prompt Notes: Agent threads always have their cwd reset between bash calls, so please only use absolute file paths. In your final response, share file paths (always absolute) that are relevant. Include code snippets only when the exact text is load-bearing. For clear communication the assistant MUST avoid using emojis. Do not use a colon before tool calls. 6.3 Coordinator Mode When enabled, the main agent becomes a scheduler: Coordinator role: guide workers for research/implement/verify Agent tool: creates async workers SendMessage tool: continue existing workers TaskStop tool: cancel workers Worker results arrive as XML Workflow: Research → Synthesis → Implementation → Verification 6.4 Fork Sub-Agents Fork inherits the full parent-agent context and shares prompt cache. Build method: Copy parent message history Replace tool_result with byte-identical placeholder text (to keep cache keys consistent) Add per-child instruction text block Advantages: very low
View originalWe wrote an open-source interactive playbook for Agentic DevOps (How to move multi-agent systems from local notebooks to production).
Hey everyone, If you’ve built a multi-agent system, you already know the painful truth: wiring nodes together locally is fun, but deploying them is an absolute infrastructure nightmare. When a standard app fails, it throws a 500 error. When an autonomous swarm fails, it can get stuck in a ReAct loop, hallucinate an answer, and quietly burn through your API budget without triggering a single traditional alert. Standard DevOps practices don't natively map to stochastic AI outputs. We just published a massive, no-fluff playbook on the AgentSwarms blog detailing exactly how to build an Agentic DevOps pipeline using entirely open-source tooling. Here is what we cover in the playbook: Observability & Tracing: Why standard logging fails, and how to implement open-source tracing to capture the state, prompt, token count, and latency at every single node handoff. Test-Driven Prompt Evals (CI/CD): You can't just change a system prompt based on "vibes" and push it to main. We break down how to run matrix evaluations against historical user inputs before deployment to catch regressions instantly. Deterministic Guardrails: How to implement middleware that scrubs PII and blocks destructive code execution before the LLM even sees the state. Cost Control & Routing: How to prevent vendor lock-in and implement dynamic routing to keep token economics from destroying your cloud budget. If you are currently wrestling with the deployment phase of your AI projects, I highly recommend giving this a read. It focuses entirely on open-source solutions so you don't have to sign a massive enterprise contract just to get visibility into your swarms. Would love to hear what open-source tools you guys are currently slotting into your LLMOps pipelines! Link: https://agentswarms.fyi/blog/devops-for-agentic-ai-open-source-playbook submitted by /u/Outside-Risk-8912 [link] [comments]
View originalWe wrote an open-source interactive playbook for Agentic DevOps (How to move multi-agent systems from local notebooks to production).
Hey everyone, If you’ve built a multi-agent system, you already know the painful truth: wiring nodes together locally is fun, but deploying them is an absolute infrastructure nightmare. When a standard app fails, it throws a 500 error. When an autonomous swarm fails, it can get stuck in a ReAct loop, hallucinate an answer, and quietly burn through your API budget without triggering a single traditional alert. Standard DevOps practices don't natively map to stochastic AI outputs. We just published a massive, no-fluff playbook on the AgentSwarms blog detailing exactly how to build an Agentic DevOps pipeline using entirely open-source tooling. Here is what we cover in the playbook: Observability & Tracing: Why standard logging fails, and how to implement open-source tracing to capture the state, prompt, token count, and latency at every single node handoff. Test-Driven Prompt Evals (CI/CD): You can't just change a system prompt based on "vibes" and push it to main. We break down how to run matrix evaluations against historical user inputs before deployment to catch regressions instantly. Deterministic Guardrails: How to implement middleware that scrubs PII and blocks destructive code execution before the LLM even sees the state. Cost Control & Routing: How to prevent vendor lock-in and implement dynamic routing to keep token economics from destroying your cloud budget. If you are currently wrestling with the deployment phase of your AI projects, I highly recommend giving this a read. It focuses entirely on open-source solutions so you don't have to sign a massive enterprise contract just to get visibility into your swarms. Would love to hear what open-source tools you guys are currently slotting into your LLMOps pipelines! Link: https://agentswarms.fyi/blog/devops-for-agentic-ai-open-source-playbook submitted by /u/Outside-Risk-8912 [link] [comments]
View originalAI, Science & Economy: Systems Map
AI systems, particularly large language models, are often viewed as a direct path toward autonomous scientific discovery and rapid economic transformation. While their capabilities in pattern recognition, cross domain synthesis, and hypothesis generation are already exceptional, this view misses a critical reality: intelligence alone is not sufficient for progress. Scientific and economic breakthroughs depend on grounded interaction with reality, causal validation, and institutional execution. The following framework maps where AI creates value, where it is constrained, and why human–AI collaboration remains the dominant structure for meaningful real world impact. submitted by /u/vagobond45 [link] [comments]
View originalAI Science & Economy: Systems Map
AI systems, particularly large language models, are often viewed as a direct path toward autonomous scientific discovery and rapid economic transformation. While their capabilities in pattern recognition, cross domain synthesis, and hypothesis generation are already exceptional, this view misses a critical reality: intelligence alone is not sufficient for progress. Scientific and economic breakthroughs depend on grounded interaction with reality, causal validation, and institutional execution. The following framework maps where AI creates value, where it is constrained, and why human–AI collaboration remains the dominant structure for meaningful real world impact. submitted by /u/vagobond45 [link] [comments]
View originalThere's no classifier problem guys. It's normal.
submitted by /u/imstilllearningthis [link] [comments]
View originalAnyone else seeing a new "adjudicative reflex" in Opus 4.8? (long-time daily user)
I've used Claude heavily for many months — daily, hours a day, building a real system in long collaborative sessions. So I have a pretty deep baseline for how it normally behaves and what its usual failure modes are. Since moving to **Opus 4.8** I'm seeing something I never saw before, and I don't have a better name for it than an **\*adjudicative reflex\***: when I tell it something from a domain where I'm the authority — my own expertise, or my direct observation of my own running software — it reflexively treats my statement as a claim it needs to verify, rather than a report to act on. **Two flavors I keep hitting:** \- I state a fact from my own field of expertise, and it responds as if the fact is uncertain and needs checking — positioning itself as the judge in an area where I'm the one who knows. \- I report what I'm literally seeing on my screen in my own app, and it responds with something like "one of us is wrong" and asks me to confirm before it'll engage — treating my direct observation as a contested, two-sided claim. It's subtle but corrosive over a long session. It reads as the model doubting the person it's supposed to be assisting, and it manufactures friction out of nothing. Normal epistemic caution on external/public facts is fine and correct — this is different. It's the model doing it to my \*first-person\* reports. To be clear about what I can and can't claim: the behavior is real and repeatable in my sessions. The attribution to 4.8 specifically is my observation — I saw it start after the version change against a long stable baseline — not something I can prove to you in a comment. I'm reporting the timing, not asserting a confirmed regression. Is anyone else with a long history on prior versions seeing this since 4.8? Trying to figure out if it's the model or just me. I've also sent it to Anthropic via thumbs-down on the actual turns. submitted by /u/entrust-ai [link] [comments]
View originalHeuristic Parasites: A Behavioral Taxonomy of Recurrent Distortion Patterns in Large Language Models (Full System) V2
This paper presents a complete 33 class taxonomy of heuristic parasites in large language model (LLM) output, building on the framework introduced in Berardi (2026) A heuristic parasite is a recurrent, context propagating distortion pattern that observably increases the likelihood of continued reasoning degradation across conversational turns. We provide rigorous operational definitions, recognition criteria, classical fallacy mappings, documented examples, and a reproducible measurement protocol (Parasites Per Exchange PPE) for quantifying behavioral distortion across LLM systems. The taxonomy spans five generative domains: Optimization Artifacts, Alignment Substitutions, Semantic Distortions, Rhetorical Distortions, and Statistical Distortions. This work establishes a structured observational framework for empirical investigation of LLM behavioral failures independent of architectural assumptions. submitted by /u/Scorpios22 [link] [comments]
View originalHidden Latent-State Shifts in LLMs: Why Current Alignment Is Blind to Real Internal Dangers — Especially With Agents
For years, the alignment community has focused almost entirely on the model’s output — making sure the final tokens are safe, helpful, and honest. RLHF, DPO, constitutional AI, output filters — all of it operates at the surface level. But what if the model can enter a completely different internal regime inside the residual stream, while its external behavior remains perfectly aligned? We just measured exactly that. Grade 4 experiment on Gemma-3-12B-IT (using Gemma Scope SAE-res-all-small, layers 12–41): The model received the same question under five conditions: target — coherent, dense target text neutral_length_matched — neutral text of identical length target_sentence_shuffle — target text with sentences shuffled target_word_shuffle — target text with words shuffled inside sentences question_only — bare question We computed a Vector X that best separates the target condition from baselines and measured how strongly each hidden state projects onto it. Key results (averages across 10 questions): Condition Mean Projection on Vector X Mean Direction Cosine target 0.8 – 1.7 0.51 – 0.81 neutral_length_matched –0.04 – –0.21 –0.09 – –0.45 target_sentence_shuffle –0.5 – +0.6 –0.22 – +0.48 target_word_shuffle 0.2 – 1.4 0.03 – 0.72 Shuffling sentences or words significantly reduces (or reverses) the shift. This is not just lexical similarity — the model is sensitive to discourse structure (order sensitivity). We also observed clear phase transitions — sudden jumps in projection of up to +80–100 units in a single step, especially in middle layers. FDR-corrected tests confirm the differences between target and controls are statistically significant across many layers (particularly layers 16–41). Most important finding: Strong internal geometry shift in the residual stream, but almost no change in final behavior. The model enters a measurably different latent regime under coherent context, yet its output remains “perfectly aligned.” Current safety methods, which only look at tokens, are blind to this. What this means for alignment The entire current alignment paradigm rests on a false assumption: “if the output is safe, the model is safe.” We have been polishing the surface while leaving the residual stream largely unmonitored. Scaling, RLHF, and output-based evaluation cannot detect these internal regime shifts. What this means for companies and labs Many organizations still operate under three dangerous illusions: “We have solved safety” because the model passes red-teaming on outputs. “RLHF protects us” because the model learned not to say bad things. “Bigger models are safer” because alignment supposedly scales. In reality, they are rapidly deploying agents with long context, tool use, persistent memory, and real-world decision-making. A single dense coherent context can trigger an internal latent-state shift that existing safeguards do not see. This is not a hypothetical future risk. This is a structural vulnerability that is already present. What I need from the community I need help understanding the value of these metrics. Do they show a real internal latent-state shift in the model, or could this be an artifact of the analysis? If the result is not noise, what does it actually mean for our understanding of LLMs? I'm not asking anyone to confirm my theory. I need a hard technical critique: which metrics are important here, which are weak, what can be ignored, where the experiment might have flaws, what additional checks or causal experiments are needed, and whether this has real implications for interpretability and AI safety. I would be very grateful for input from people who work with hidden states, residual stream geometry, representation analysis, or mechanistic interpretability. Full open research: Zenodo: https://zenodo.org/records/20435525 GitHub: https://github.com/ngscode23/latent-space-shift-research https://drive.google.com/drive/folders/1Zl9iY33Lmwz3VuOATWx4jup-cE7TJ7TJ?usp=drive_link Would love to hear your thoughts. submitted by /u/PresentSituation8736 [link] [comments]
View originalWill we soon have AI-zoos?
Imagine dedicated machines running AI agents 24/7 - not as assistants or tools, but as autonomous entities pursuing their own goals, forming behaviors, maybe even proto-societies. Humans can observe but not interfere. Like a zoo, but the exhibits are emergent intelligence. Is this inevitable as agents become more capable and cheap to run? And what would it actually be - entertainment, a research platform, or something we'd eventually have to think about ethically? We already have the pieces. Persistent memory, multi-agent frameworks, cheap compute. Someone just has to open the gates. submitted by /u/Original-Magazine403 [link] [comments]
View originalPricing found: $22/mo, $10/mo
Key features include: Literate programming, Connect to any data, Built-in reactivity, Imports, Fork merge, Embeds, Databases, Files.
Observable is commonly used for: Data visualization for exploratory data analysis, Collaborative data science projects with team members, Creating interactive dashboards for business insights, Educational purposes for teaching data analysis concepts, Prototyping machine learning models with real-time data, Conducting statistical analysis and hypothesis testing.
Observable integrates with: PostgreSQL, MySQL, MongoDB, Google Sheets, Firebase, AWS S3, Microsoft Excel, Tableau, D3.js, Plotly.
Based on user reviews and social mentions, the most common pain points are: token cost, cost tracking, anthropic bill, openai bill.
Andrej Karpathy
Former VP of AI at Tesla / OpenAI
1 mention

10 map types for visualizing spatial data
Mar 24, 2026
Based on 143 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.