Mathpix
Convert images and PDFs to LaTeX, DOCX, Overleaf, Markdown, Excel, ChemDraw and more, with our AI-powered document conversion technology.
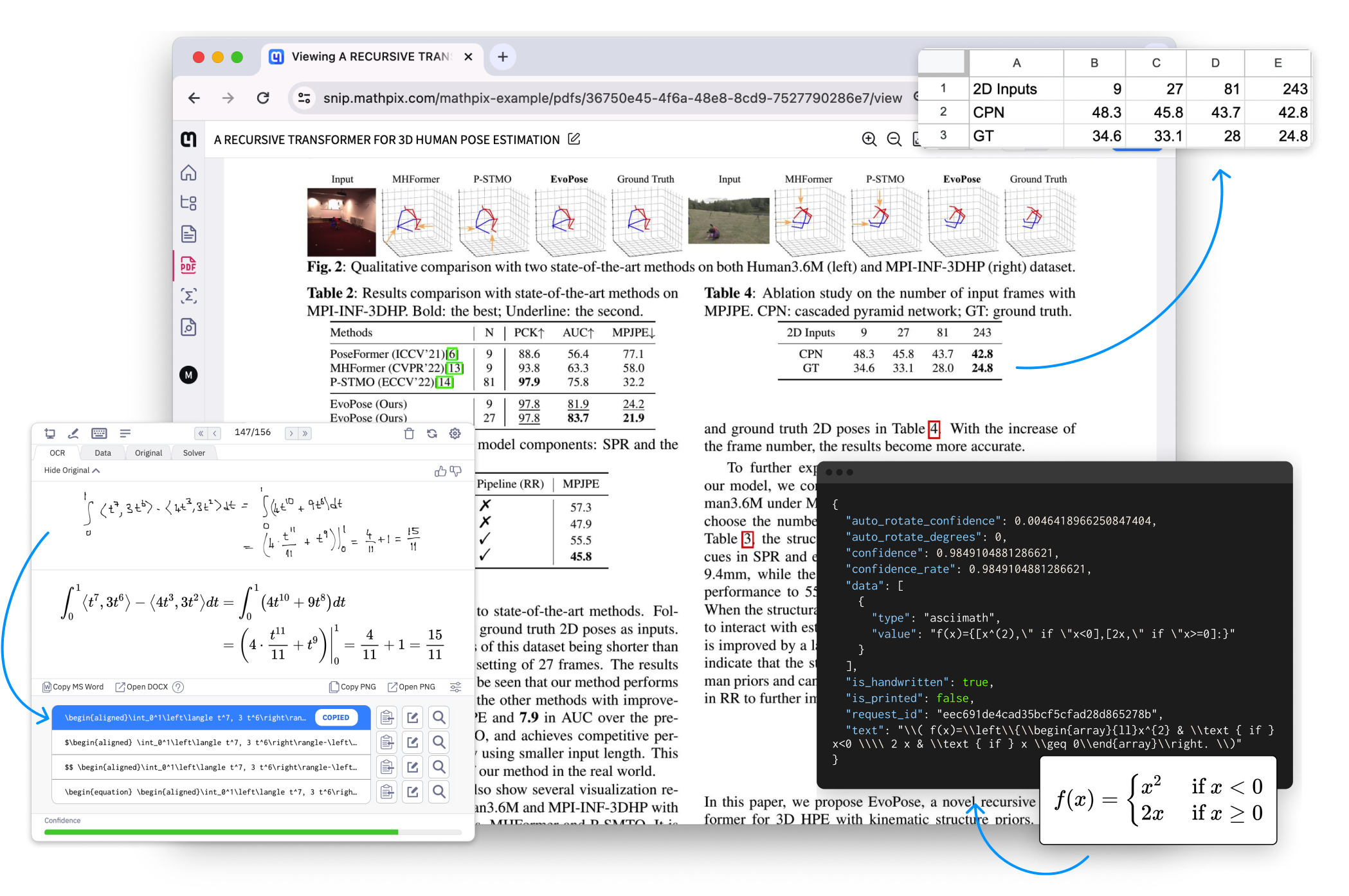
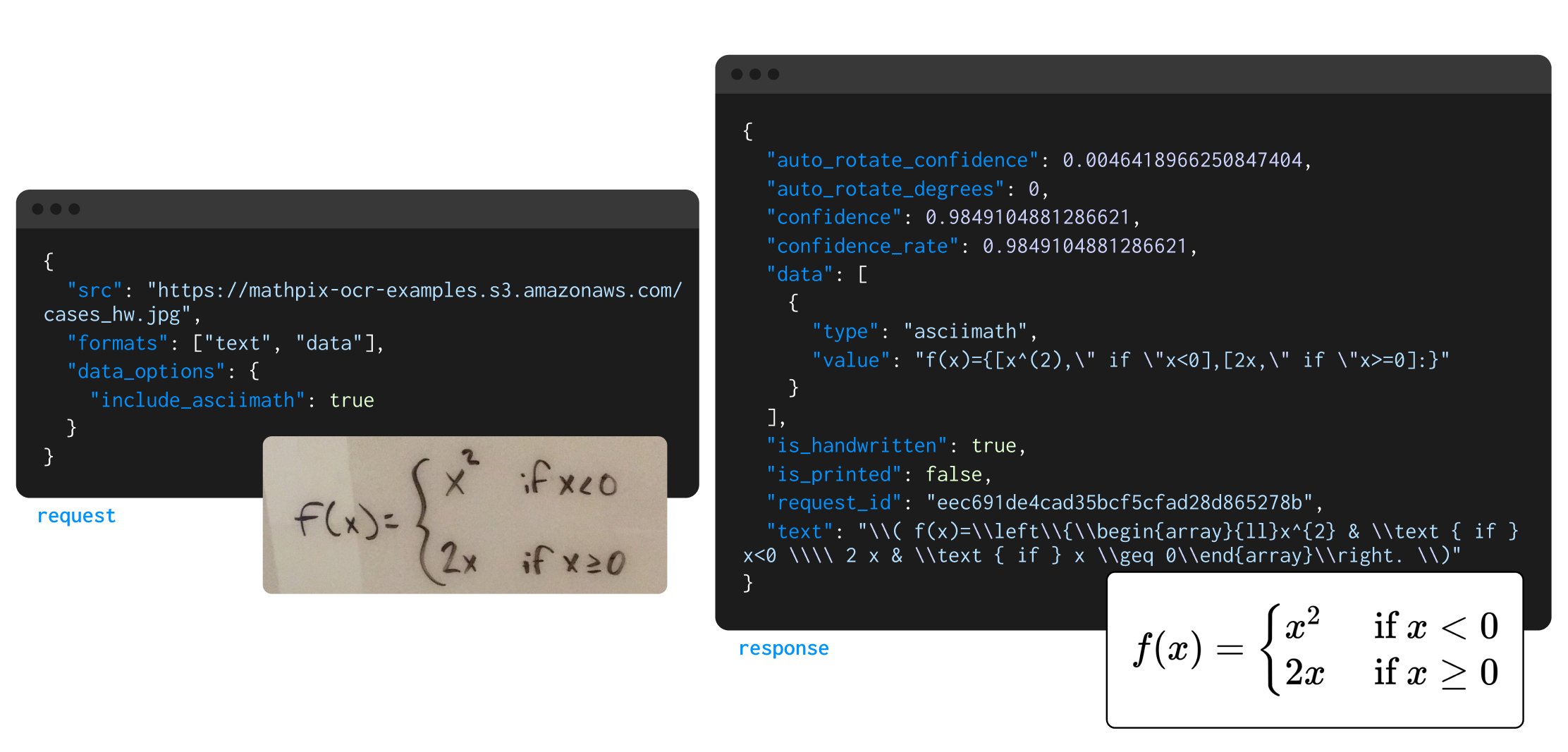
Quickly and accurately convert PDFs and images to searchable, exportable, and machine readable text. We offer robust APIs for developers and an OCR-powered productivity app for researchers. The most accurate OCR technology with deep STEM functionality, including math, chemistry, handwriting, tables, foreign languages, and full PDF document conversion. Accurately convert large PDF and image libraries into machine readable text files in hours, not months. We process millions of pages of unstructured PDFs and images per hour so you get the accurate data needed to train and tune your model fast. Our tools make teaching, writing, publishing, and collaborating on scientific research easy. Markdown and AI-powered collaborative editing environment for researchers with world-class image and PDF conversion tools. Desktop app that allows you to OCR content from your screen and copy math and chemistry to your clipboard with a single keyboard shortcut. Compatible with LaTeX, Markdown, MS Word, and more. Mathpix claims to offer PDF → LaTeX / Markdown conversion. I was skeptical… but the results are quite amazing! This is changing my life. Mathpix's "Snip" will let you screenshot an equation, and it will return the LaTeX code. Works passably on handwriting, and nearly flawlessly on pdf equations. An old idea, but I really like talking with PDFs instead of reading them. I use Mathpix to extract the text (does the best job of preserving tables), and GPT to discuss it. It's amazing how long it took humanity to realize that no human should ever create a LaTeX document from scratch. This is one of the greatest mathematical discoveries of the last two decades.
Textract
Amazon Textract is a machine learning (ML) service that uses optical character recognition (OCR) to automatically extract text, handwriting, and data
Automatically extract printed text, handwriting, layout elements, and data from any document Drive higher business efficiency and faster decision-making while reducing costs. Extract key insights with high accuracy from virtually any document. Scale up or scale down the document processing pipeline to quickly adapt to market demands. Securely automate data processing with data privacy, encryption, and compliance standards. Accurately extract critical business data such as mortgage rates, applicant names, and invoice totals across a variety of financial forms to process loan and mortgage applications in minutes. Better serve your patients and insurers by extracting important patient data from health intake forms, insurance claims, and pre-authorization forms. Keep data organized and in its original context, and remove manual review of output. Easily extract relevant data from government-related forms, such as small business loans, federal tax forms, and business applications, with a high degree of accuracy. As part of the AWS Free Tier, you can get started with Amazon Textract for free. The Free Tier lasts for three months, and new AWS customers can analyze up to: Total pages processed = 100,000 Total pages processed = 2,000,000 Price per page = $0.0015 for first 1 million and $0.0006 for pages after 1 million Total pages processed = 5,000 pages Price for page with table = $0.015 Price for page with form (key-value pair) = $0.05 Price per page with Queries = $0.015 Total pages processed = 2,000,000 pages Price for page with Tables, Forms and Queries = $0.070 for the first one million and $0.055 for the next one million Let’s assume you want to extract data from 100,000 invoices using the Analyze Expense API. The pricing per page in the US West (Oregon) region for 1 million pages is $0.01 and you process 100,000 invoices. The total cost would be $1,000. See the calculation below: Total pages processed = 100,000 Let’s assume you want to extract data from 1,500,000 invoices using the Analyze Expense API. The pricing per page in the US West (Oregon) region for one million pages is $0.01 per page and $0.008 per page after one million. The total cost would be $14,000. See the calculation below: Total pages processed = 1,500,000 Price per page = $0.01 for the first 1 million and $0.008 for the next 500,000 Let’s say you want to extract information from 100,000 identity documents using the Analyze ID API. The pricing per page in the US West (Oregon) Region for 100,000 pages is $0.025 per page for up to 100,000 pages. The total cost would be $2,500. Total pages processed = 100,000 Let’s say you want to extract information from 600,000 identity documents using the Analyze ID API. The pricing per page in the US West (Oregon) Region for 100,000 pages is $0.025 per page and $0.01 per page after 100,000. The total cost would be $7,500. Total pages processed = 600,000 Let’s say you want to extract information from 200,000 pages of mort
Mathpix
Textract
Mathpix
Textract
Pricing found: $0.0015,, $150., $0.0015, $0.0015, $150
Only in Mathpix (1)
Mathpix

Textract
No screenshots
Mathpix
Textract